Groq accelerates generative AI models by a factor of 10-20
The AI hardware start-up Groq has created special chips that accelerate common language models to an extremely high degree. This can now be tested for everyone with the popular Mixtral,…
RSRalf SchukayUpdated Jun 23, 20264 min read Human reviewed
✓ ReviewedLast updated June 23, 2026 by Ralf Schukay
The AI hardware start-up Groq has created special chips that accelerate common language models to an extremely high degree. This can now be tested for everyone with the popular Mixtral, Mistral and Llama 2 models on the Groq website.
Groq in the test: 10-20 times faster GenAI models
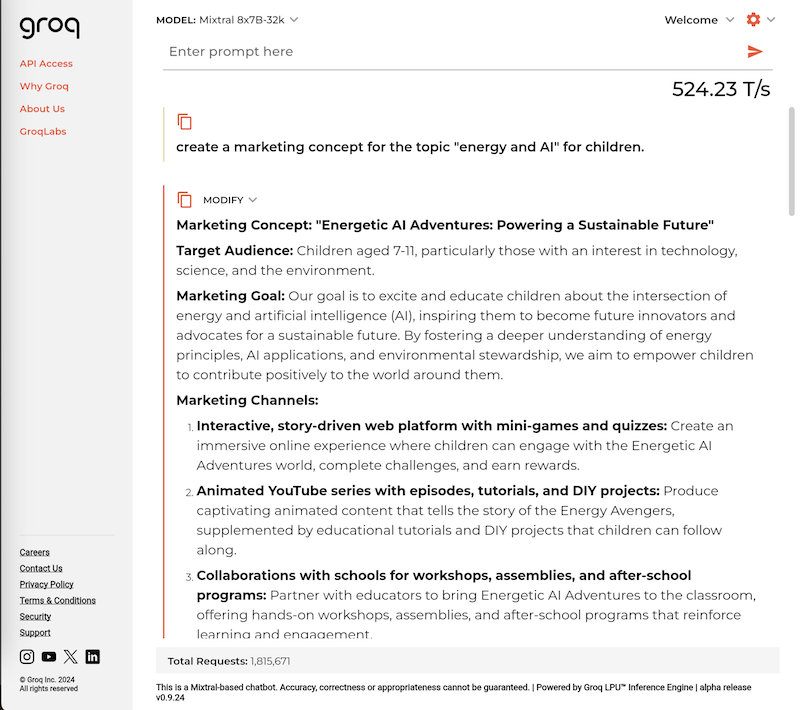
In the test, we asked the Mixtral model “8x7B 32K” to create a marketing concept. As a result, the model generated 500 words (3,700 characters), with Mixtral returning the result with almost no waiting time. After only 4 seconds the concept was completely generated. The results are returned live.
Groq can be experienced live here without registration (tip: do it!)
Result: The marketing concept generated by Mixtral
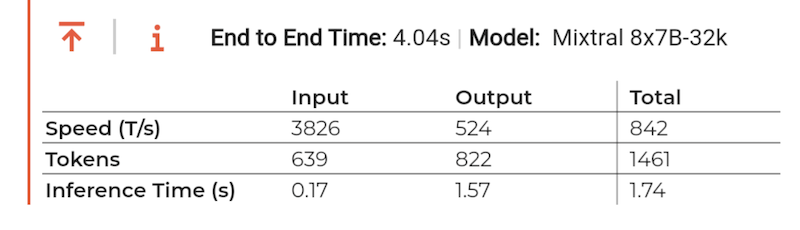
Groq’s performance with the Mixtral model: 1.7 seconds for 500 words
Although Groq needed a total of 4 seconds, this also includes waiting times due to parallel use by other users and latency times on the Internet. In fact, the model only needed 1.7 seconds to generate the 500 words (see Inference Time, broken down by the duration of processing the input prompt and the text output). This corresponds to a throughput of an incredible 840 tokens per second (approx. 20x faster than ChatGPT)
The advantages of accelerated GenAI models
The advantages are obvious: a fast LLM enables significantly faster text creation, translations, code generation or simply research. We estimate that productivity can be increased by a factor of 2-3 for typical tasks. The advantages of code-based use of LLMs via API are much greater, as the full throughput of 500 tokens per second can be exploited here.
Which language models does Groq support?
The following open source AI models can currently be tested directly on the Groq website free of charge and without registration:
Mixtral 8x7B 32K (considered “almost as good” as GPT-4)
Mistral 7B 8K (roughly comparable to GPT-3.5-Turbo)
Llama 2 70B 4K (Meta’s OpenSource model)
Groq has thus made some of the currently most promising open source LLMs even better. These exceed the speed of GPT-4 (“the current leading language model”) by far.
However, Groq is not limited to these models, but can in principle accelerate all models and also games, as the optimized chips have a high throughput and low latency due to their design.
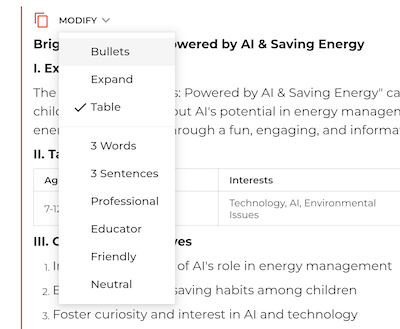
Another feature on the Groq website: Output results as a table
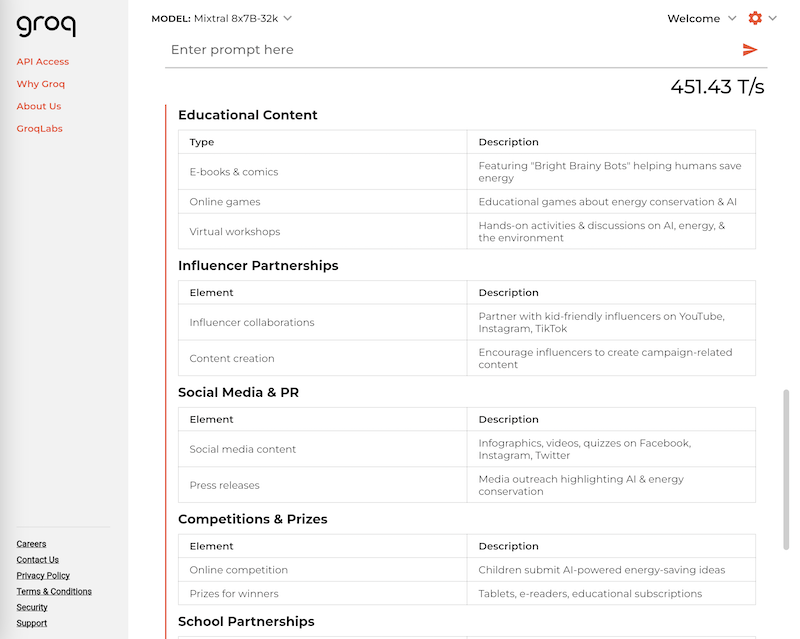
If you want to use the powerful and accelerated text AIs free of charge, you can even discover another practical feature on the Groq website: You can quickly adjust the output tonality, have it summarized in 3 sentences or especially handy: reformat it as a table.
Example: Output of the generated content as tables
Conclusion and outlook: AI will be extremely fast in 2024
Groq makes working with AI even better, because who hasn’t experienced it: AI often doesn’t return the desired result. With Groq acceleration, this is no longer a problem, as the generated text can be corrected and refined in just a few seconds.
OpenAI is also working in parallel to accelerate its popular language model using chips produced in-house. And NVIDIA is also continuously working on increasing the performance of its leading AI chips. It is expected that the popular ChatGPT and Microsoft’s Copilot will be just as fast by 2024.
The AI race has literally picked up speed once again thanks to technologies such as Groq, which will significantly drive the adaptation and use of AI in everyday life.
TL;DR: Groq is important because it focuses on very fast AI inference, which can change the user experience for chat, agents, customer support, and real-time applications. Speed is valuable when latency directly affects workflow quality.
Editorial recommendation: Evaluate Groq when response time is a product requirement, not just a benchmark trophy. The best use cases are real-time assistants, high-volume inference, and agent loops where every second compounds.
When Groq-style fast inference matters
Factor
Priority
Why it matters
Real-time chat assistants
Strong fit
Low latency improves interaction quality.
Agentic workflows
Strong fit
Multiple model calls make speed compound across steps.
Batch content generation
Maybe
Throughput may matter more than single-response latency.
Highly specialized reasoning tasks
Evaluate carefully
Model quality and task fit still matter as much as speed.
FAQ
What is Groq known for?
Groq is known for fast AI inference hardware and services designed to reduce latency for language model applications.
Why does AI inference speed matter?
Lower latency improves user experience and can make multi-step agent workflows faster and more practical.
Is speed more important than model quality?
No. Speed matters most when the model is good enough for the task and latency affects the product experience.
Put AI into practice
Turn one repetitive task into a working AI workflow.
Use the AI Automation Playbook for practical, step-by-step workflows built for small businesses and lean teams.
Ralf Schukay ist Co-Gründer von AI Rockstars und spezialisiert auf AI-Automatisierung und Enterprise-Lösungen. Er testet und vergleicht KI-Tools für den professionellen Einsatz und hilft Teams, mit Workflow-Automatisierung produktiver zu arbeiten.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.