How it works: Text → Embedding model → Vector → Stored in DB → Similarity search via cosine/dot product
Bottom Line: If you’re building any AI application that needs to search or retrieve information, you need a vector database.
If you want to create AI applications such as a semantic search, you need a suitable vector database. These make embeddings available at lightning speed and scale better than classic SQL or NoSQL stores. We present popular options from SaaS to open source – including strengths, costs and typical use cases.
What is a vector database?
Imagine you have thousands of texts or images and you want to find similar content in an intelligent way. Instead of comparing exact terms, each piece of content is translated into a so-called vector – a kind of mathematical fingerprint (called “embeddings”). These vectors store the meaning instead of just the words. Similar terms also have similar vectors, i.e. they are close to each other. The cosine distance and other methods are then used to compare how close, for example, an AI query for “apple” is to other vectors for “pear” or “horse”. Fruit is closer together. Vectors thus form the basis for a perfect search, regardless of how the term is spelled. Learn more: Introduction to Vector Databases
Vector databases help to store these vectors efficiently and find similar ones in real time – a Google search for meaning, so to speak. They are used when classic keyword searches are no longer sufficient – e.g. for chatbots, RAG searches in company documents, search engines or recommendation systems. Article: The best RAG-Templates for n8n
Overview: Vector databases for AI applications
When selecting a suitable vector database for AI projects, the first thing to consider is the license model, as open source solutions have the advantage of having complete control over the code and being able to operate the solution independently of the provider. The hosting model also plays a role: some solutions can only be installed locally, while others are available entirely as a cloud service. If you want minimal maintenance, it is better to choose a cloud-managed solution. The ability to support hybrid searches (combination of keyword and vector searches) can be crucial for many RAG scenarios. Those looking to scale should also look for distributed architecture and GPU support. Last but not least, LLM/RAG compatibility is relevant – for example through APIs, integrations or native support for tools such as LangChain or LlamaIndex.
Easy integration into existing Redis infrastructure
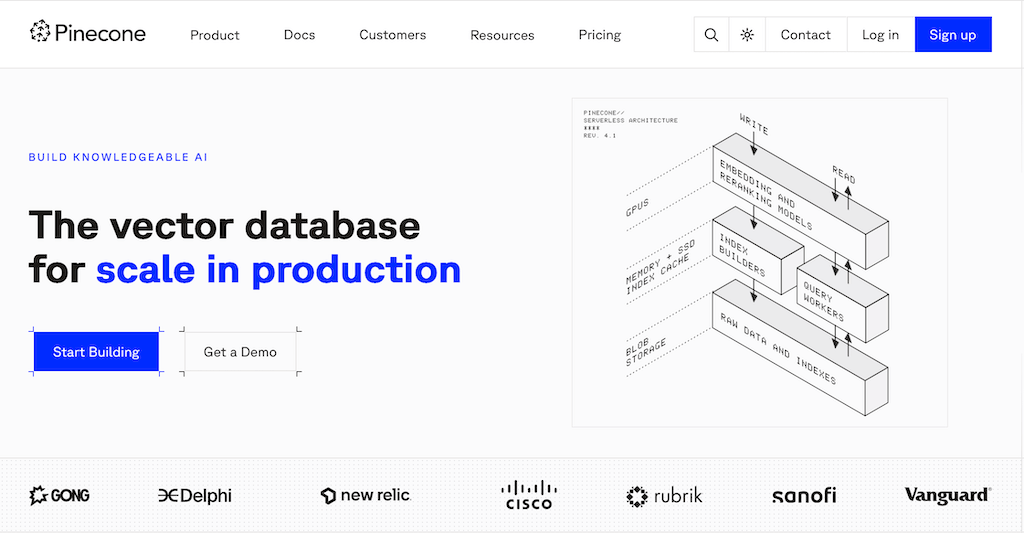
Pinecone – Cloud-native vector database
<p”>Just start, don’t manage it yourself. Pinecone is a fully managed cloud service where you don’t have to worry about servers or sharding. The serverless architecture automatically scales from a few thousand to billions of vectors. A clear dashboard shows query latencies, memory consumption and index statistics in real time. Thanks to EU regions and encryption-at-rest, your solution remains GDPR-compliant. SDKs for Python, JavaScript and Go as well as plug-ins for LangChain, LlamaIndex and Haystack drastically shorten the time to prod.
Costs: Free tier (5 GB), from 0.096 $/GB/month (Starter)
Distribution: very high ★★★★
Special features: Fully managed scaling, vector SQL only, GDPR compliance via EU regions, deep LLM integrations (LangChain, LlamaIndex).
Suitable for: Productive RAG and SemSearch APIs without infrastructure effort.
Weaviate – an open source all-rounder
Weaviate’s motto is: Semantic search graph = flexible platform. Weaviate runs as a single binary in a Docker container or as a cluster in Kubernetes and is therefore perfect for self-hosting. A built-in transformer pipeline can either generate embeddings itself or use external models. Semantic and relational queries can be elegantly combined via the GraphQL interface. Versioning and vector sharding ensure linear scaling. The community continuously provides modules for RAG, images and even multimodal search.
Costs: Open source (MIT), cloud from 0 $/month (0.5 vCPU)
Distribution: high ★★
Special features: Hybrid query (BM25 vector), GraphQL API, module system (transformers, Q&A), GDPR-friendly thanks to self-hosting.
Suitable for: Projects that want to combine relation and semantics.
Milvus – For large-scale performance
When billions of embeddings are needed. Large companies such as AT&T, Nvidia, Paypal and Walmart rely on the popular open source vector database. Milvus relies on a microservice architecture with separate query, proxy and data nodes and thus achieves enormous parallelism. IVF-, HNSW- and GPU-capable indexes allow you to fine-tune speed and accuracy. Time-travel queries make snapshots of historical data retrievable – practical for ML retraining. Sharding and tiered storage (e.g. S3 or MinIO) keep costs under control even with petabyte sizes. Milvus is also available as a hosted version under the name“Zilliz Cloud“.
Costs: Open source (Apache 2.0), Zilliz Cloud from 0 $ (trial)
Distribution: high ★★
Special features: IVF, HNSW, GPU support, time-travel queries, horizontal scaling via shards.
Suitable for: Image, audio or text corpora in the terabyte range.
Qdrant – Speed for the productive environment
Fast, secure, written in Rust. Qdrant uses SIMD optimizations for extremely low latencies even during streaming updates. Payload filtering allows complex filters via metadata without an additional datastore. With gRPC, REST and native clients, you can integrate Qdrant into any ecosystem. A snapshot feature backs up complete indices during operation. The roadmap includes hierarchical clustering and disk-based HNSW levels for very large data sets.
Costs: Open source (Apache 2.0), cloud from 0 $/month (starter)
Distribution: medium ★☆
Special features: gRPC REST, payload filtering, streaming updates, GDPR mode.
Suitable for: Latency-critical real-time receivers in production.
Chroma – lightweight for prototyping
“Batteries included” for LLM playgrounds. Chroma runs in-process within your Python script, so you don’t need an external database. Persistence is handled by DuckDB or SQLite – ideal for local experiments. Thanks to Simplified API, three lines of code are enough to store and query documents. An experimental sync function replicates your store in a remote cluster. This keeps Chroma small at first and allows it to grow as required.
Special features: Purely in-process (Python), persistent DuckDB store, minimal API calls, seamless in LangChain/LlamaIndex.
Suitable for: Fast proof-of-concepts, local-first apps, smaller knowledge bases.
FAISS – classic from the AI lab
The vector library from Meta. FAISS is not a server DB, but a C / Python library that you integrate directly into ML pipelines. It supports GPUs, half-precision and quantization, allowing huge data sets to fit into the graphics memory. IVF PQ or OPQ also drastically reduce memory requirements. Since FAISS has no network layer, you achieve maximum raw performance – you build scaling and persistence yourself. Many data teams use FAISS as a low-level engine behind their own APIs.
Special features: Extremely performant with large amounts of data, supports CPU & GPU, no server operation (library, no database), requires coding skills.
Suitable for: Research, ML prototyping, custom vector search in Python.
If you are already using the popular Redis database. Redis Stack extends known data structures with a vector data type with HNSW indices. This allows you to combine classic hash and set queries with semantic searches in the same database. With RedisGears, you can write in-DB pipelines such as embedding calculations in Python or JavaScript. Enterprise editions bring active-active replication and RedisAI modules for inference on the fly. If you want to make minimal changes to your infrastructure, Redis is a quick shortcut.
Costs: Redis Stack free of charge, Redis Cloud depending on the plan
Distribution: high ★★
Special features: Simple integration, vector support via Redis modules (HNSW), familiar API handling, fast setup.
Suitable for: RAG & vector search in existing Redis environment.
Conclusion: Which vector DB is suitable for which purpose?
The choice of vector database depends heavily on the maturity of your project:
You want SaaS & get started right away? → Pinecone.
Maximum flexibility & open source? → Weaviate or Qdrant.
Petabyte ambitions? → Milvus.
Just test it out? → Chroma.
Build it yourself or extend Redis? → FAISS or Redis.
Tip for starting: Test the database briefly with your data set. Pay attention to latency, throughput and of course the costs – then nothing stands in the way of high-performance AI applications.
Frequently Asked Questions – Vector Databases
A vector database stores embeddings and enables semantic similarity search. Learn more.
Unlike relational databases using exact match queries, vector databases work with similarity comparisons in vector space. Elastic explains.
Embeddings are numerical vector representations of data (e.g. text or images) that capture semantic meaning. IBM on embeddings.
They enable semantic search, RAG chatbots, personalization, and unstructured data handling. What is RAG?.
Use them for semantic or unstructured search – avoid for purely relational data needs. Intro to vector search.
RAG, chatbots, semantic search, recommender systems, and multimodal AI. Chroma use cases.
Depends on the system – many offer soft deletes, versioning, or snapshot-based updates. Qdrant collections.
Indexing, compression (e.g. PQ), GPUs, and distributed architecture are key. FAISS index types.
A fast way to find similar vectors with minimal accuracy loss. Wikipedia: ANN.
It depends on your data, scaling needs, hosting preferences, and LLM integration. DigitalOcean guide.
“Vector databases are the unsung heroes of modern AI applications. While everyone talks about LLMs, it’s the vector DB that makes the difference between a chatbot that hallucinates and one that actually knows your data.”
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

 Weaviate’s motto is: Semantic search graph = flexible platform. Weaviate runs as a single binary in a Docker container or as a cluster in Kubernetes and is therefore perfect for self-hosting. A built-in transformer pipeline can either generate embeddings itself or use external models. Semantic and relational queries can be elegantly combined via the GraphQL interface. Versioning and vector sharding ensure linear scaling. The community continuously provides modules for RAG, images and even multimodal search.
Weaviate’s motto is: Semantic search graph = flexible platform. Weaviate runs as a single binary in a Docker container or as a cluster in Kubernetes and is therefore perfect for self-hosting. A built-in transformer pipeline can either generate embeddings itself or use external models. Semantic and relational queries can be elegantly combined via the GraphQL interface. Versioning and vector sharding ensure linear scaling. The community continuously provides modules for RAG, images and even multimodal search.