Meta’s Llama 4 sets new standards in artificial intelligence with its innovative mixture-of-experts architecture, native multimodality and extended context windows.
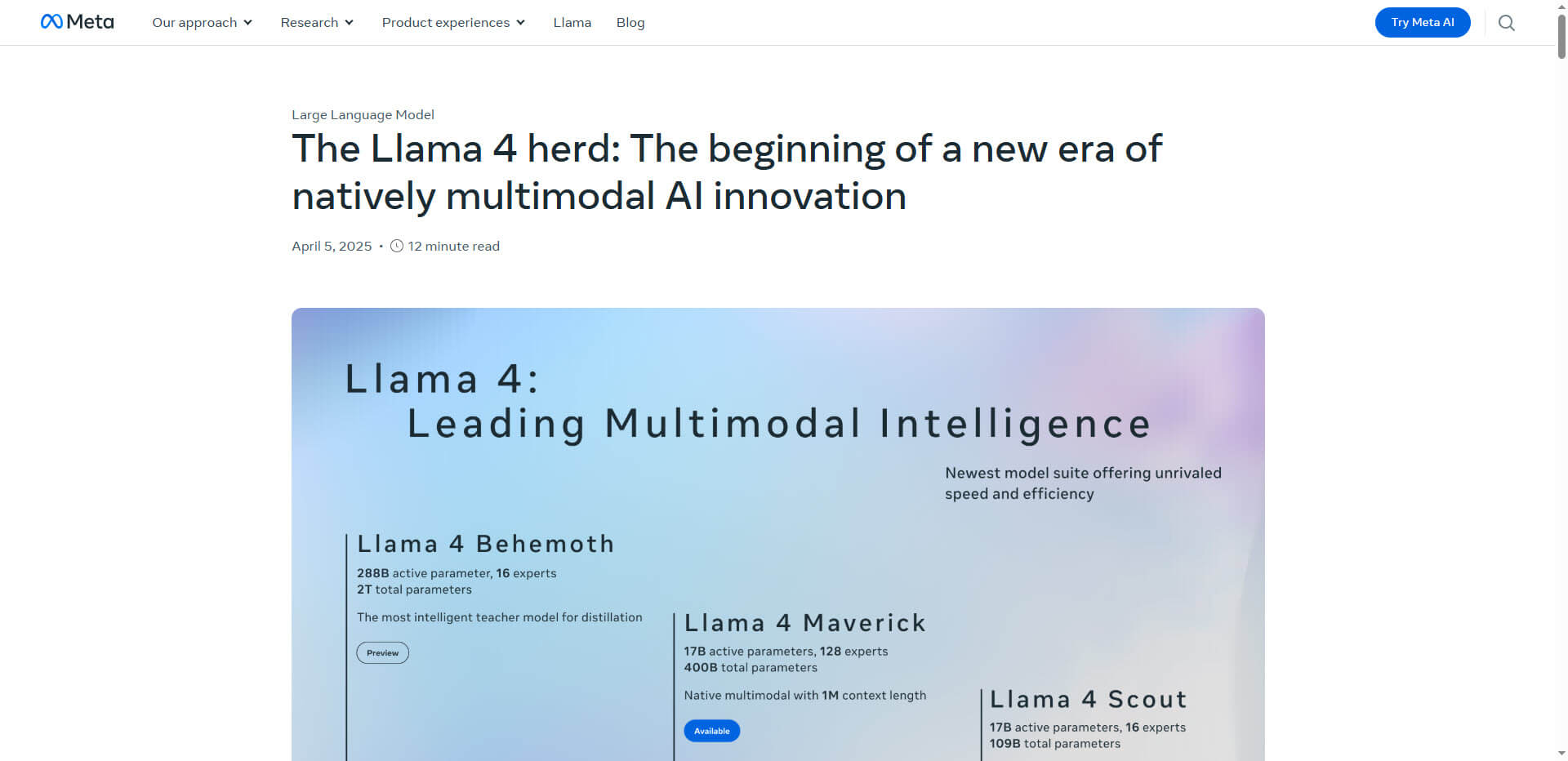
Meta’s latest AI family – consisting of the Scout, Maverick and as yet unreleased Behemoth models – addresses three key challenges of modern AI systems: computational efficiency, multimodal processing and context limitations. With a revolutionary Mixture-of-Experts (MoE) architecture, Llama 4 activates only 2-5% of its parameters per token, drastically reducing computational costs while keeping up with significantly larger models in terms of performance.
Llama 4 model overview
The Maverick variant manages to activate only 17 billion parameters per query out of a pool of 400 billion parameters, enabling 95% higher computational efficiency compared to conventional models.
Particularly noteworthy is Llama 4’s approach to multimodal processing. Unlike previous models that process text and image data separately, Llama 4 uses an early fusion method that integrates different modalities at the input level. Using a MetaCLIP-based vision encoder and special cross-modal attention mechanisms, the model can handle complex visual speech processing tasks with remarkable accuracy.
The models have been trained with over 30 trillion tokens of multimodal data and can process up to 48 images simultaneously – a capability that is particularly relevant for applications in image analysis and document-based queries.
The Scout model also impresses with a 10 million token context window made possible by the innovative iRoPE (Interleaved Rotary Position Embedding) architecture. This technology allows the model to process large documents and capture both local and global contexts. Benchmarks show a 98% retrieval accuracy with 10 million token codebases.
Summary:
Llama 4 utilizes a mixture-of-experts architecture that activates only 2-5% of parameters per request, increasing computational efficiency by 95%
Native multimodal processing through early fusion enables simultaneous processing of up to 48 frames
10 million token context window outperforms GPT-4 by a factor of 80 and enables the analysis of large documents
Performance comparisons show superiority over GPT-4o and Gemini 2.0 while reducing energy consumption by 40%
First enterprise integrations at Snowflake and Cloudflare demonstrate practical use cases in document analysis and real-time image processing
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.