Chinese AI model Kimi K2 from Moonshot AI turns the global AI landscape on its head with trillion-parameter architecture and superior performance at a tenth of the cost of Western competitors.
Released in July 2025, Kimi K2 is based on an innovative Mixture-of-Experts (MoE) architecture with one trillion parameters, of which only 32 billion are activated during inference. This frugal activation allows the model to run on commodity hardware while achieving performance on par with proprietary models such as GPT-4 and Claude Sonnet. The model has been trained on 15.5 trillion tokens and achieves particularly strong results in the areas of programming and autonomous problem solving.
Moonshot AI’s pricing strategy fundamentally disrupts the market: at 0.15 dollars per million input tokens and 2.50 dollars per million output tokens, Kimi K2 undercuts Western competitors tenfold. OpenAI’s GPT-4 costs significantly more, while Anthropic’s Claude Sonnet 4.5 is priced at 3 dollars input and 15 dollars output per million tokens. This aggressive pricing makes frontier-grade AI capabilities economically accessible to startups and smaller companies for the first time.
Technical innovations include the novel MuonClip Optimizer, which prevents training instability on trillion-parameter models, and Quantization-Aware Training, which enables INT4 quantization with minimal performance loss. These optimizations reduce the model size to 594 gigabytes while doubling the inference speed.
Benchmark performance exceeds expectations
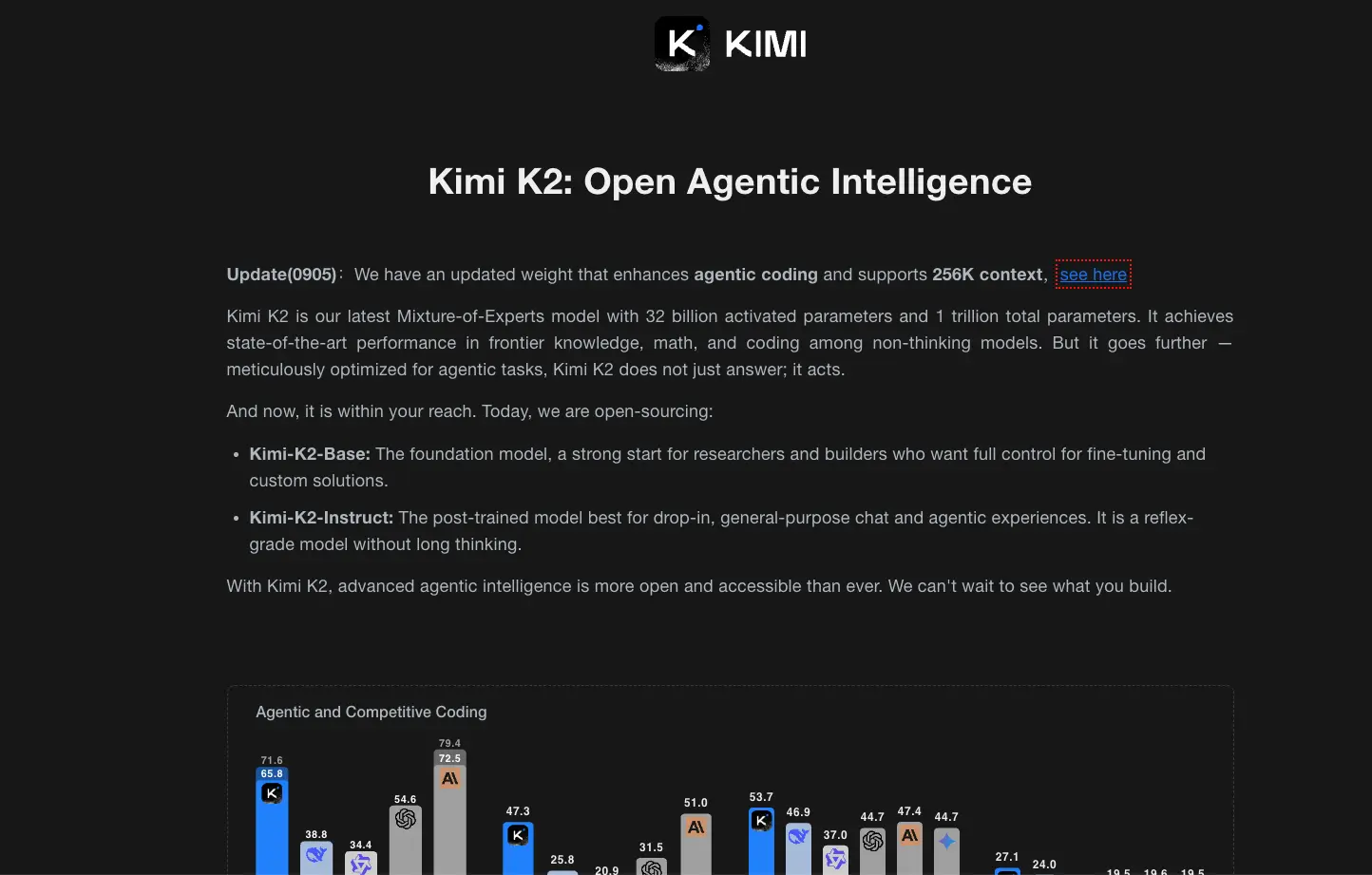
In practical tests, Kimi K2 achieves impressive results: 53.7% accuracy on LiveCodeBench v6 (#1 among open-source models), 65.8% on SWE-Bench Verified for autonomous software engineering tasks and 75.1% on GPQA-Diamond for graduate-level scientific problems. On the LMSYS Arena ranking, the model ranks 5th overall and 1st among open source alternatives based on over 3,000 user reviews.
The Kimi K2 Thinking variant, which followed in November 2025, extends the capabilities with advanced reasoning processes and can execute up to 200-300 sequential tool calls in a single problem-solving session. The “Heavy Mode” executes eight parallel reasoning paths simultaneously and significantly improves accuracy on difficult problems, achieving 44.9% on Humanity’s Last Exam and outperforming GPT-5 Thinking (41.7%) and Claude Sonnet 4.5 Thinking (32.0%).
Geopolitical impact of the Chinese AI offensive
The release of Kimi K2 marks a turning point in the global AI competition between the USA and China. Industry analysts refer to it as a “DeepSeek moment”, in which unexpected Chinese breakthroughs shake the perception of Western dominance in AI development. Chamath Palihapitiya of Social Capital commented that Kimi K2 is “significantly more powerful and many times cheaper than OpenAI and Anthropic”, while Martin Casado of 16z estimates that 80 percent of AI entrepreneurs use Chinese open source models.
The structural cost advantages of Chinese AI development are reflected in training costs: Kimi K2 cost about 4.6 million dollars to train – a fraction of the billions that OpenAI and Anthropic invest in research and development. This efficiency results from access to low-cost computing infrastructure, strategic government support and domestically sourced semiconductor supply chains that provide effective alternatives such as Nvidia’s H20 architecture despite export restrictions.
Executive Summary
– Moonshot AI’s Kimi K2 utilizes MoE architecture with 1 trillion parameters, but enables only 32 billion for inference – Price advantages of 10x over GPT-4 and Claude Sonnet with comparable or better performance – Top performance in coding benchmarks with 53.7% on LiveCodeBench v6 and 65.8% on SWE-Bench Verified
– K2 Thinking variant executes up to 300 sequential tool calls and outperforms Western competitors – Open-source availability under modified MIT license democratizes access to frontier-grade AI – Geopolitical implications signal shift in global AI competition in favor of Chinese development – Quantization-optimized for deployment on commodity hardware with 2x speed increase – 15.5 trillion token training data with innovative MuonClip optimizer for stable trillion-parameter scaling
Source: Moonshot





