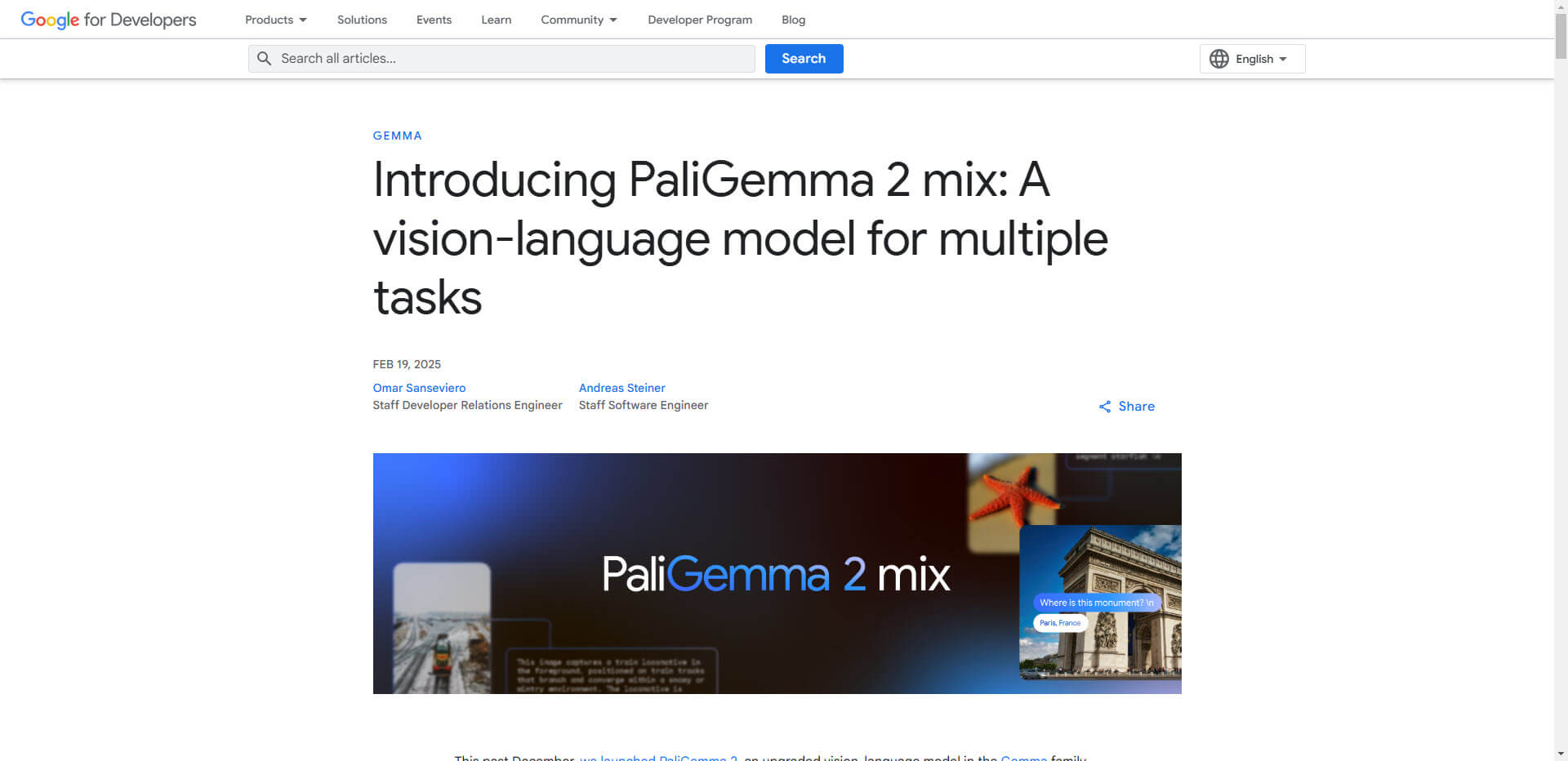
Introduction of PaliGemma 2 mix: Google takes vision language models to a new level
Never before has the fusion of machine vision and speech processing been so sophisticated. With the release of PaliGemma 2 mix, Google is setting new standards in the development of…
FSFlorian SchröderUpdated Mar 18, 20263 min read Human reviewed
Never before has the fusion of machine vision and speech processing been so sophisticated. With the release of PaliGemma 2 mix, Google is setting new standards in the development of multimodal AI.
With PaliGemma 2 mix, Google launches an improved version of its PaliGemma 2 model and simplifies access to vision language models through intelligent adaptations. The three available variants – 3 billion, 10 billion and 28 billion parameters – cover a wide range of use cases and hardware capacities and appeal to both established developer platforms and new user groups.
In particular, the support for multi-resolution image processing (224px², 448px² and 896px²) sets the model apart. It promises exceptional performance results, from basic operations such as image labeling to more demanding tasks such as optical character recognition (OCR) with high resolution or segment-based image analysis. Particularly attractive for companies: The integration requires no code changes for existing users, which minimizes implementation costs.
Progress in specific industries
The extended functionality has already achieved impressive results in specialized areas. In healthcare, the model has achieved state-of-the-art performance in the analysis of medical image data such as the MIMIC-CXR dataset. PaliGemma 2 mix also shows its strength in pharmaceutical research: molecular structure recognition with a precision of 94.8 percent opens up new possibilities in drug development.
Special attention is also paid to the financial sector. With precise data recognition from complex table structures, the model could point the way forward for financial analysts and business intelligence tools. PaliGemma 2 mix also makes important progress in the area of accessibility. Image descriptions for visually impaired users have been made significantly 20 percent more factually accurate – a remarkable step towards inclusion.
Technological structure and industry potential
The model combines the SigLIP vision encoder with the Gemma language model and supports both general and specialized tasks through its three-stage pretraining process. The high efficiency with which the model remains flexible through comprehensive training on different data sets and can be used out-of-the-box is remarkable.
In the long term, the potential of PaliGemma 2 mix could accelerate the development of visual and speech-based applications by enabling research institutions and companies to develop innovative applications in areas such as music transcription, accessibility or document processing. There is a strategic advantage for SMEs in particular, as the accessible model sizes enable cost-efficient testing.
Summary of the key aspects
Flexibility through scalability: Selectable model parameter sizes (3B, 10B and 28B) facilitate use according to the available hardware and tasks.
New industry standards: Outstanding performance in medical, pharmaceutical, financial and accessibility applications.
Easy integration: Existing users can upgrade to PaliGemma 2 mix without code changes.
With PaliGemma 2 mix, Google is once again placing a technological focus on multimodality and could revolutionize value creation in industrial AI applications for various sectors.
Florian Schröder ist Co-Gründer von AI Rockstars und Experte für KI-Strategien im Marketing. Er berät Unternehmen bei der Integration von AI-Tools wie ChatGPT, Claude und Gemini in ihre Workflows. Mit über 10 Jahren Erfahrung in digitalem Marketing verbindet er technisches Know-how mit praxisnahen Anwendungen.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.