Fine-tuning OpenAI’s GPT model – benefits and coding guide
Fine-tuning allows a language model to adapt to your own specific data, significantly improving response quality. Here, we demonstrate how to enhance OpenAI’s GPT-3.5 Turbo using fine-tuning through Python and…

Fine-tuning allows a language model to adapt to your own specific data, significantly improving response quality. Here, we demonstrate how to enhance OpenAI’s GPT-3.5 Turbo using fine-tuning through Python and the OpenAI API or Microsoft Azure. Highlight: we’ve provided a link to the complete Jupyter notebook.
Updates:
- 9.5.2025: GPT-4.1 now supports Reinforcement-Finetuning OpenAI API docs
- 20.8.2024: GPT-4o can now be fine-tuned Read announcement
- 22.8.2023: GPT-3.5 Turbo now supports fine-tuning To OpenAI’s announcement
- 22.8.2023: OpenAI announces that GPT-4 will support fine-tuning starting in fall 2023
📖 This article is part of our comprehensive ChatGPT guide. Read the full guide →
What is Fine-tuning?
A large language model (LLM) such as OpenAI’s GPT-3.5 Turbo can already provide comprehensive answers to many questions. However, it provides insufficient answers when you want to query specific knowledge. Examples: Products of a company, answer typical hotline queries and more. Fine-tuning helps here, because you can easily retrain missing knowledge for tasks or industries without having to train your own base model. This would also become very difficult, because this often requires high-end GPU hardware, training data and specialized knowledge. Fine-tuning is made precisely to make a language model even more accurate and reliable after the fact.
OpenAI lists the following improvements through fine-tuning:
- Controllability: fine-tuning makes the model respond more accurately to instructions, such as set language. This prevents chatbots from digressing, which can happen occasionally.
- Consistent formatting: the fine-tuned model provides better responses in any format, ideal for technical applications such as code generation (example: generating a Python or JSON file)
- Brand tonality: the chat model speaks in a company’s specific tonality, which reinforces brand identity (e.g., formal vs. formal, casual vs. serious, inspirational vs. fact-based, etc)
- Prompt savings: fine-tuning can also save API costs and efforts for prompts. This is because if the fine-tuning model knows exactly what to do, “up to 90% of token costs can be saved” (example given by OpenAI, freely translated).
Costs for fine-tuning models
The costs of training and using your own fine-tuned OpenAI GPT models is calculated by tokens. 1000 tokens correspond to about 750 English words. Compared to the normal base model, the fine-tuned model costs about 3x more for input, 4x more for output. Training costs extra.
For a training file with 100,000 tokens trained over 3 epochs, the expected cost would be: ~$0.90 USD with gpt-4o-mini-2024-07-18
Read also: GPT-5.3 Codex: The autonomous coding agent is here
For up-to-date pricing information see the OpenAI API docs
Recommended: Xcode 26.3: Agentic Coding with Claude & Codex
Examples: How fine-tuning helps
Overall, fine-tuning improves AI models by allowing them to perform their tasks more reliably and accurately. It’s not just about making AI smarter, but also making it more relevant and valuable to the end user. Here are some real-world examples.
- Better chatbot customer support: fine-tuning allows a chatbot to include company-specific information in its responses. For example, it could say, “Please see what product ID is printed on the original packaging of the T-301 cell phone” to effectively help customers.
- Better content: Editorial teams can train their chatbot, such as GPT-3.5, to match the specific tone and style of their audience. This means that content generated by the AI is better suited to the target audience and comes across as more authentic.
- Improved translations: For companies operating in specific geographic regions, the model can be customized to better capture and translate regional language nuances or industry-specific jargon. Example: January is called “Jänner” in Austria.
- Optimized customer service: A fine-tuned model can better understand and respond more accurately to customer queries. This can lead to faster and more satisfactory responses from customers, which increases customer satisfaction.
- Privacy and compliance: fine-tuning can train the model to avoid certain information or data that could be sensitive to an organization. This is especially important for industries that must comply with strict privacy regulations.
Possibilities of implementation
The GPT model can be used via the OpenAI API or via Microsoft Azure OpenAI Service.
First, we show how this works with the OpenAI API. The easiest way to use fine-tuning is a) via the frontend of the OpenAI Playground, which is quick and easy. Alternatively, you can also do this b) via Python code, which has the advantage that you can integrate fine-tuning into your own build processes.
We will then briefly outline the path via Microsoft Azure OpenAI.
Variant 1: Fine-tuning GPT via OpenAI Playground
Duration: 15 minutes, Recommended for: Non-coders, quick attempts
The easiest way to fine-tune OpenAI’s GPT is via the OpenAI Playground.
Steps for fine-tuning via Playground:
- Open the OpenAI Playground: https://platform.openai.com/playground
- Navigate to the fine-tuning area: https://platform.openai.com/finetune
- Click on “Create” at the top right
- Select basic model (e.g.: gpt-3.5-turbo-1106, higher models only possible as soon as OpenAI has published this)
- Upload training data (you can read more about how to create this under “Variant 2”)
- Upload validation data (optional, allows you to measure the improvement through fine-tuning)
- Click on “Create”
- Wait (approx. 10 min, depending on the amount of training data)
- Click on “Playground” on the left
- The fine-tuned model is now permanently available in the Playground and you can use it there directly in the chat or alternatively address it via API.
Configuration of the fine-tuning model:

Training: You can see how far the model has already been trained and recognize errors

Result: Fully trained model

Use the fine-tuning model: In the Playground or via API

Variant 2a: Fine-tuning of GPT via Python and OpenAI API
Duration: 30 minutes (depending on experience), Recommended for: Python coders
Fine-tuning can be implemented with OpenAI’s GPT model (example: GPT 3.5 Turbo) with just a few lines of code. The OpenAI API can be called simply via curl call from the console/terminal. However, LLM developers mostly work with Python, which is why we show an example here as a Python-Jupyter notebook.
Fine-tuning steps:
- Prepare data
- Upload data to OpenAI
- Start fine-tuning job
- Query fine-tuning model
Here we go.
Step 0: Preparing the Jupyter notebook and the imports
We use JupyterLab as the IDE. However, you can also use the code in Google Colab, but then you have to upload the file with the training data via Google Drive and connect Colab to Google Drive.
First of all, necessary libraries are installed. After that you should restart the Jupyter kernel (via menu under Kernel > Restart Kernel). The libraries are imported and API variables are set. You need your OpenAI API key and the organization ID. You can find it in your OpenAI account.
# upgrade openai library, restart kernel pip install --upgrade openai # imports and settings import os import openai import json import datetime OPENAI_API_KEY = "sk-12345" # TODO: Enter API key ORG_ID = "org-12345" # TODO: Enter Org ID TRAINING_FILE_NAME = "data-finetuning-10examples.jsonl" # training file in JSONL format # set API key openai.api_key = OPENAI_API_KEY
Step 1: Prepare fine-tuning data
Fine-tuning training data one prepares in question/answer form so that the GPT model can learn it clearly. As an example, we are improving a customer service chatbot. For this, we generated dummy customer service data via ChatGPT with GPT-4 in the required format (prompt: see notebook).

How should fine-tuning training data be prepared?
The OpenAI API requires at least 10 examples for fine-tuning. In real use, you need significantly more training data. As a rule of thumb, 500-1000 examples could be a good orientation here. In general, when using training data, it is important to use training data that is of good quality, i.e., as correct, clear, consistent, complete, and easily machine-readable as possible. The OpenAI API can read the data in JSONL format.
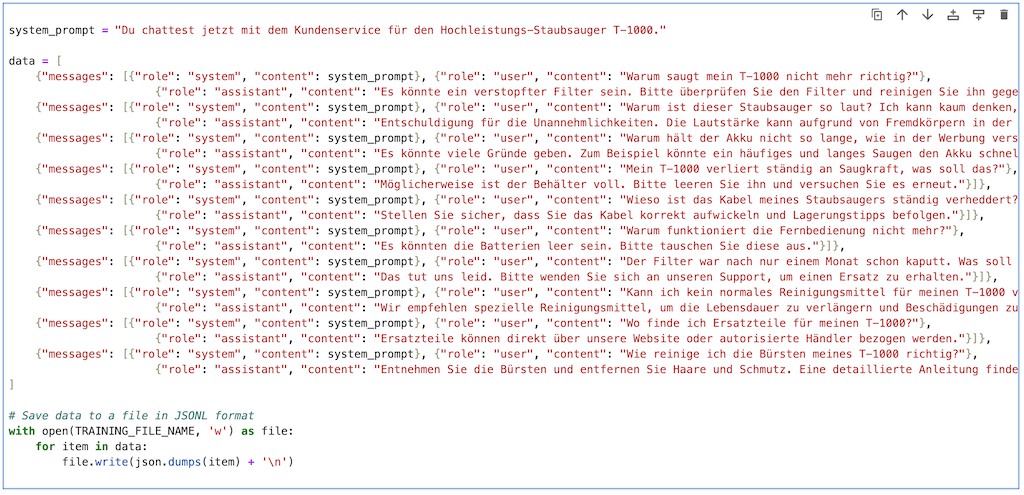
The Python code to define the fine-tuning training data (excerpt):
system_prompt = "You are now chatting with customer service for the T-1000 heavy duty vacuum cleaner."
data = [
{"messages": [{"role": "system", "content": system_prompt}, {"role": "user", "content": "Why is my T-1000 not vacuuming properly anymore?"},
{"role": "assistant", "content": "It could be a clogged filter. Please check the filter and clean it if necessary."}]},
{"messages": [{"role": "system", "content": system_prompt}, {"role": "user", "content": "Why is this vacuum cleaner so noisy? I can barely think when it's running!"},
{"role": "assistant", "content": "Sorry for the inconvenience. The volume may increase due to foreign objects in the brush. Please check it."}]},
{"messages": [{"role": "system", "content": system_prompt}, {"role": "user", "content": "Why does the battery not last as long as promised in the advertisement?"},
{"role": "assistant", "content": "There could be many reasons. For example, frequent and long vacuuming could drain the battery faster. Make sure to charge the vacuum cleaner after each use."}]},
{"messages": [{"role": "system", "content": system_prompt}, {"role": "user", "content": "Can't I use a normal cleaner on my T-1000?",
{"role": "assistant", "content": "We recommend special cleaning agents to extend the life and prevent damage."}]}
]
# Save data to a file in JSONL format
with open(TRAINING_FILE_NAME, 'w') as file:
for item in data:
file.write(json.dumps(item) '
')
Step 2: Upload training data
Next, we upload the training data as a file via the OpenAI API. Important: Do not upload any sensitive data. We need the TRAINING_FILE_ID to start the fine tuning in the next step.
response_upload = openai.File.create( file=open(TRAINING_FILE_NAME, "rb"), purpose='fine-tune' ) TRAINING_FILE_ID = response_upload.id # print upload response to check if successful response_upload
Step 3: Start fine-tuning job
Now the fine-tuning job is started and the model is trained.
job = openai.FineTuningJob.create(training_file=TRAINING_FILE_ID, model="gpt-3.5-turbo-0613")
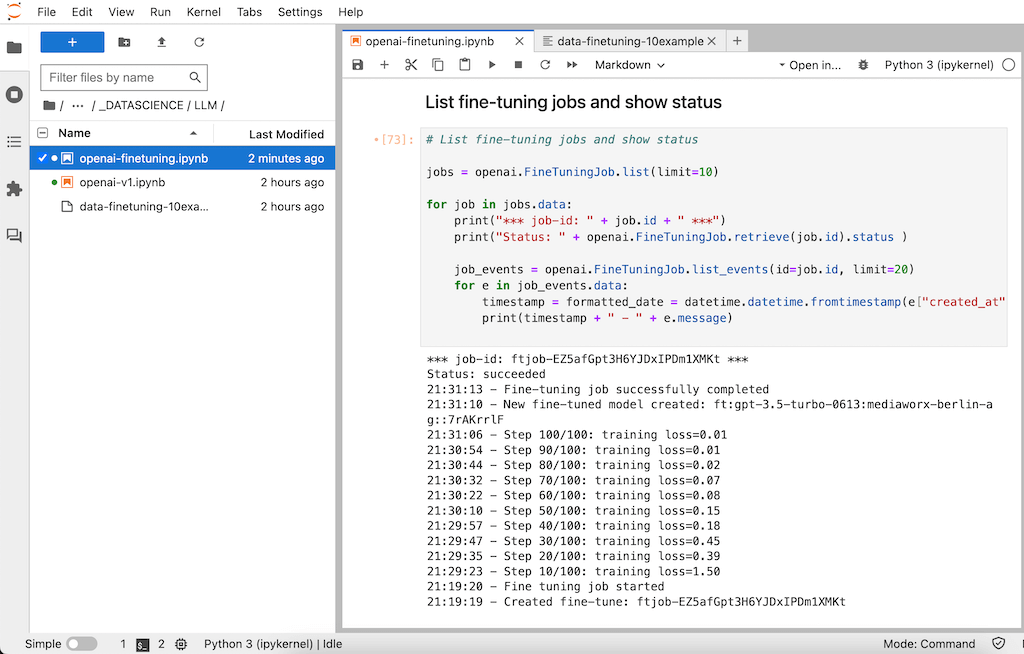
This process takes about 12 minutes for our 10 dummy entries. You can check at any time how far the process has progressed. To do so, you can list all running fine-tuning jobs with their job events.
# List fine-tuning jobs and show status
jobs = openai.FineTuningJob.list(limit=10)
for job in jobs.data:
print("*** job-id: " job.id " ***")
print("Status: " openai.FineTuningJob.retrieve(job.id).status )
job_events = openai.FineTuningJob.list_events(id=job.id, limit=20)
for e in job_events.data:
timestamp = formatted_date = datetime.datetime.fromtimestamp(e["created_at"]).strftime('%H:%M:%S')
print(timestamp " - " e.message)
The result after a successfully performed fine-tuning looks like this:
Step 4: Query fine-tuning model
After successful fine-tuning your own model is available. This has the name “ft:” like “fine-tuning”, followed by the used base model (here “gpt-3.5-turbo-0613”) and the organization name from your OpenAI account, and an 8-digit ID.
MODEL = "ft:gpt-3.5-turbo-0613:YOURORGNAME::7rAKrrlF"
completion = openai.ChatCompletion.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are now chatting with customer service for the high performance vacuum cleaner T-1000."},
{"role": "user", "content": "I want to clean my T-1000 with Pril. Can you do that?"}
]
)
print(completion.choices[0].message)
The result: the customer service chatbot answers more accurately
We now ask our customer service chatbot if we can clean our vacuum cleaner with Pril. According to the training data, it should answer this query in such a way that it is more likely to recommend a special cleaning agent. We have deliberately formulated the query in such a way that GPT cannot read it 1:1 from the training data.
Fine-tuning training data:
- Customer: “Can’t I use a normal cleaning agent for my T-1000?”
- Service: “We recommend special cleaning agents to extend the life and prevent damage.”
Fine-tuning Model Response:
- Customer: I want to clean my T-1000 with Pril. Is that okay?
- Service: We recommend only special cleaning agents to avoid damage.

Variant 2b) Reinforcement Fine-Tuning of GPT-4.1 via API
As an improved fine-tuning method, OpenAI offers Reinforcement Fine-Tuning (RFT) starting with GPT-4.1. This option is currently available via API and requires coding. Reinforcement Fine-Tuning allows OpenAI models to be optimized using a programmable Grader (output: percentage between 0 and 1) instead of fixed labels (output: 0 or 1), enabling the model to be specifically fine-tuned to individual quality metrics such as style, safety, or domain knowledge.
- Developers define a grader,
- upload training and test data, and
- start the fine-tuning job,
- the model is iteratively adjusted based on grader scores.
Especially practical: RFT is ideal for preparing LLMs for structured outputs (e.g., JSON) and demanding specialized tasks, as the training loop is automated until the optimal result is reached
https://platform.openai.com/docs/guides/reinforcement-fine-tuning
Variant 3: Fine-tuning of GPT via Microsoft Azure OpenAI
Those who use the solution via Microsoft Azure, which is more data protection-compliant for many companies, can also easily fine-tune their GPT model. Here too, there are two methods: either simply via a) the Azure OpenAI Studio web frontend or b) using Python code via the Azure OpenAI API.
Finished model in Azure OpenAI Studio:

Limits and problems with fine-tuning
Fine-tuning makes language models more accurate and is very easy to apply retrospectively to models that support this technique (e.g. GPT). However, as with all training processes, problems can also arise and should therefore be recognized.
- Data quality and diversity: The model is only as good as the data used to train it. Insufficient, biased or unrepresentative fine-tuning training data can lead to poor performance. You should therefore combine and ensure a mix of good responses in the fine-tuning data.
- Overfitting: Fine-tuning with too specific or limited a set of data can lead to the model being over-fitted to this specific data and therefore responding poorly to more general or new data.
- Catastrophic forgetting: An interesting phenomenon in fine-tuning is the complete forgetting of actually known information and response capabilities. This can occur when the neural network adjusts its weights to learn new data, but loses the adaptations that were important for predicting the previously learned data. Even GPT-4 can then lose some of its impressive abilities.
- Ethics and bias: Language models can reflect existing social and cultural biases. This can lead to racism, sexism and other forms of discrimination. Therefore, extensive fine-tuning data and the newly trained model should be checked for this.
Conclusion
- Fine-tuning improves the performance of the already powerful GPT model even more and is very easy to implement.
- Fine-tuning is possible with OpenAI’s ChatGPT 3.5 since August 2023, version GPT-4 will be supported from autumn 2023.
- There is no absolute control over the output of a question/answer system like a chatbot even with fine-tuning. But it significantly improves the quality and provides much more stability of the results. The output of your fine-tuned model should therefore be tested cleanly via quality assurance and model evaluation before deployment.
- When training, one should also take into account not to send sensitive data to the OpenAI API.
Bonus: Jupyter notebook for fine-tuning the GPT model
Here is the link to the notebook including dummy training data:
https://github.com/RalfSchukay/finetuning-gpt-openai/blob/main/README.md
Learn more about fine-tuning
- DeepLearning.ai: Finetuning Large Language Models – Course for fine-tuning GPT 3.5 Turbo with videos and coding exercises (duration: 1h, free)
- OpenAI: Guide: Finetuning – All steps to fine-tuning explained in detail
- OpenAI: API Reference: Finetuning – The OpenAI API
- OpenAI: Pricing – Costs for using all models, incl. fine-tuned models
- Youtube: Fine Tuning GPT-3.5-Turbo – Guide with Code Walkthrough
AI Rockstars verdict
TL;DR: Fine-tuning OpenAI models is useful when a team needs consistent style, format, classification behavior, or domain-specific response patterns. It is not the right first step when better prompting, retrieval, or examples would solve the problem.
Editorial recommendation: Try prompt engineering and retrieval before fine-tuning. Fine-tune only when you have enough high-quality examples, stable output requirements, and a clear evaluation set.
When to fine-tune instead of prompt
| Factor | Priority | Why it matters |
|---|---|---|
| Consistent output format | Good fit | Fine-tuning can make structured responses more reliable. |
| Brand or support style | Good fit | Examples can teach tone and response patterns. |
| Missing factual knowledge | Usually RAG first | Retrieval is better for changing or source-heavy knowledge. |
| Unclear task definition | Do not fine-tune yet | Bad examples produce bad model behavior. |
FAQ
When should you fine-tune an OpenAI model?
Fine-tune when you need repeatable behavior, style, format, or classification patterns that prompting alone cannot provide.
Is fine-tuning better than RAG?
Not always. RAG is usually better for factual, changing, or source-dependent knowledge.
What data do you need for fine-tuning?
You need high-quality examples, consistent desired outputs, and an evaluation set to test whether behavior improves.
Related AI Rockstars Guide
Turn one repetitive task into a working AI workflow.
Use the AI Automation Playbook for practical, step-by-step workflows built for small businesses and lean teams.




