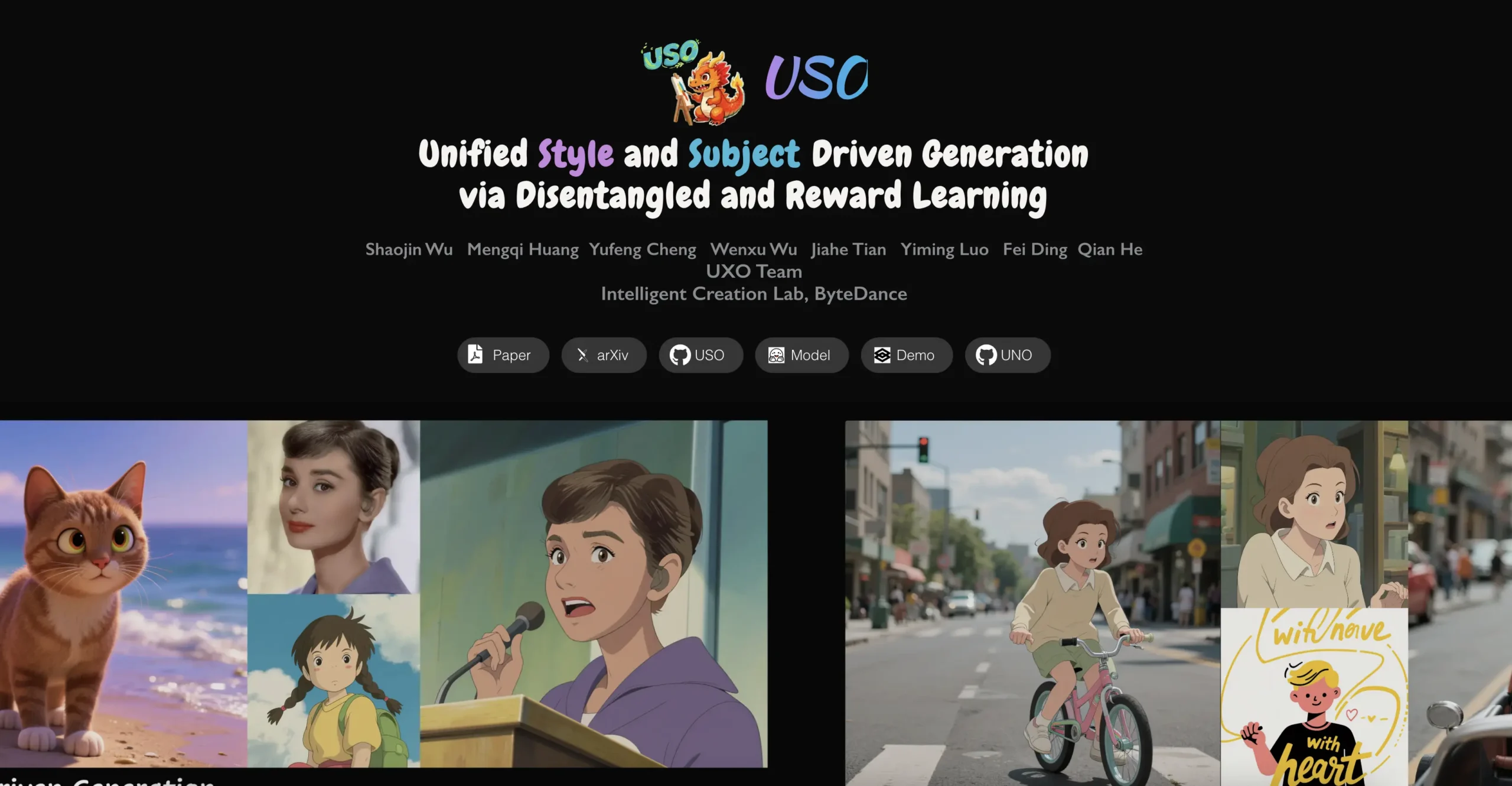
ByteDance is transforming image generation with a groundbreaking framework that successfully merges two previously separate AI domains. The new system, called USO (Unified Style and Subject-Driven Generation), represents a fundamental paradigm shift and achieves state-of-the-art results with simultaneous control of style and subject features.
ByteDance’s UXO Team Intelligent Creation Lab released a framework in August 2025 that solves a long-standing challenge in AI image generation. Traditionally, style-driven and subject-driven generation have been treated as competing tasks, with optimizations in one area typically leading to degradations in the other. However, USO demonstrates that these tasks can be mutually reinforcing when unified through innovative cross-task co-disentanglement techniques.
The system is based on a MM-DiT (Multimodal Diffusion Transformer) architecture with a novel unified attention mechanism. Instead of traditional cross-attention between modalities, USO links all input tokens – text, style, content and noisy latents – into a unified sequence that is processed by joint self-attention.
Technical innovations and performance data
USO’s two-stage progressive training addresses the optimization problems that limited previous unified approaches. Stage 1 (Style Alignment Training) focuses exclusively on the alignment of style features with existing text processing capabilities. Stage 2 (Content-Style Disentanglement Training) introduces the full complexity of joint style-subject generation while maintaining the stable foundation achieved in Stage 1.
The performance results on the DreamBench evaluation dataset demonstrate the superiority of the approach. USO achieves the highest reported DINO similarity score of 0.777 and a CLIP-I score of 0.838, representing significant improvements over previous state-of-the-art methods. The CLIP-T score of 0.317 confirms a strong text-to-image alignment while preserving subject features.
The framework utilizes the SigLIP encoder for style processing instead of traditional VAE encoders – a crucial design decision for capturing richer, more abstract style cues. Content images pass through a separate processing pipeline with a frozen VAE encoder optimized for preserving subject identity and structural information.
Cross-task triplet dataset and evaluation
The development of the USO dataset of approximately 200,000 carefully curated triplets represents the first large-scale dataset specifically designed for uniform style-subject generation. The innovative cross-task triplet curation framework generates comprehensive training data in the format ⟨style reference, content reference, stylized target⟩ through two specialized expert models.
USO-Bench establishes the first comprehensive benchmark for the joint evaluation of style similarity and subject fidelity. The benchmark evaluation methodology includes three different task domains: pure subject-driven generation, pure style-driven generation, and joint style-subject scenarios. The evaluation metrics cover multiple dimensions of generation quality and address both objective and subjective aspects of image generation.
The Style Reward Learning (SRL) paradigm provides additional supervision to improve model performance on style fidelity and subject consistency. Style similarity rewards use dense embeddings of specialized style encoders for continuous feedback on stylistic alignment, while subject consistency rewards employ established metrics such as CLIP-I and DINO similarity measures.
Practical applications and future perspectives
USO’s unified capabilities enable a wide range of practical applications that were previously difficult or impossible to realize. Creative content generation particularly benefits from the ability to reposition subjects into entirely new compositions while maintaining both identity and style consistency. This proves particularly valuable for storytelling applications where consistent characters need to appear in different stylistic contexts.
Commercial design applications utilize USO’s unified approach for scenarios that require brand consistency across different visual styles. Marketing campaigns can efficiently generate coherent visual content while adapting to different aesthetic contexts. The real-time generation capabilities make the framework suitable for interactive applications where users can explore different stylistic options.
The open-source availability of the framework ensures that these advances benefit the broader research community while encouraging collaborative improvement and customization. Memory optimization strategies including fp8 quantization modes reduce peak memory consumption to around 16GB and provide access to advanced generation capabilities on consumer hardware.
Summary
- ByteDance releases USO framework for unified style and subject-driven image generation with state-of-the-art performance
- Innovative MM-DiT architecture with unified attention mechanism successfully unifies two previously competing AI domains for the first time
- Two-stage progressive training solves optimization conflicts through style alignment training and content-style disentanglement training
- New benchmark records with DINO score 0.777 and CLIP-I score 0.838 with strong text-image alignment at the same time
- USO-Bench establishes first comprehensive evaluation standard for joint assessment of style similarity and subject fidelity
- 200.000 curated triplets in the USO dataset enable robust generalization across different application domains
- Open source availability and memory optimization democratize access to advanced generation capabilities on consumer hardware
Source: GitHub





