With the release of Llama 3.2-Vision, Meta is setting a new benchmark in the world of multimodal artificial intelligence. These models offer comprehensive solutions that seamlessly integrate text and image information, opening up a wide range of applications for developers and companies.
Under the name Llama 3.2-Vision, Meta is presenting models in two sizes, with 11 billion and 90 billion parameters. They are specially optimized for tasks that require both text and images. These models combine Llama 3.1 language capabilities with new visual recognition and image clarification options using a separately trained vision adapter. The use of Supevised Fine-Tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF) ensures that the models match human preferences in terms of helpfulness and safety.
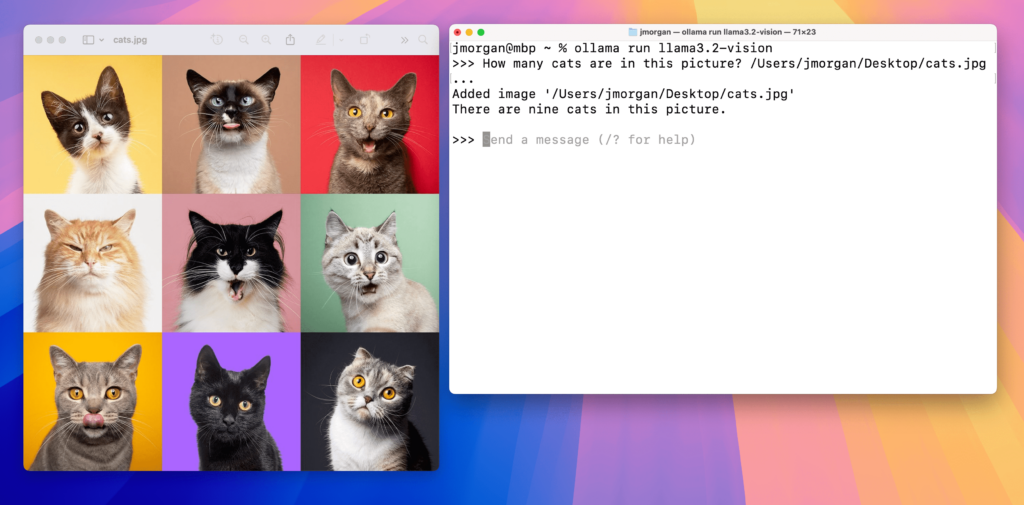
Llama3.2 Vision: Image Q&A ; Source: Ollama
The range of applications includes captioning, where the models are able to understand scenes and generate appropriate descriptions, and image-to-text queries, which is like a search engine that understands both image and text information. The visual foundation capability allows models to identify specific objects or areas in an image using natural language descriptions.
A notable innovation from Meta is the integration of the models into edge and mobile devices. Partnerships with companies such as Arm, MediaTek and Qualcomm play a central role in delivering powerful AI to devices that have limited computing resources. This enables developers to create applications that are widely used in everyday life. The community license of Llama 3.2 offers the possibility of both commercial and scientific use and opens the doors for applications in data and model development.
The release of the Llama 3.2 vision models represents a significant step forward in AI research. The advantage of multimodal models lies in their ability to bridge the gap between different forms of data, providing versatile and flexible solutions. This advancement underpins the relevance of AI in areas such as education, design and medicine, where both image and speech understanding are important.
The most important facts about the update:
Llama 3.2-Vision offers models in two sizes: 11 and 90 billion parameters.
Application areas include captioning and visual foundation.
Models benefit from Supervised Fine-Tuning and Reinforcement Learning with Human Feedback.
Integration into edge and mobile devices through partnerships with leading manufacturers.
Community license supports commercial and scientific applications.
This update signals a significant shift in the variety of ways AI can be used in the future and encourages discussion about the immense potential of multimodal models.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.